
Di balik percakapan yang terasa ringan dengan model bahasa besar (LLM), terdapat jejak energi yang tidak kecil. Interaksi yang tampak sederhana—mengetik pertanyaan, menerima jawaban—sebenarnya ditopang oleh infrastruktur komputasi berlapis: ribuan akselerator, jaringan berkecepatan tinggi, dan sistem pendingin yang bekerja tanpa henti. LLM bukan sekadar perangkat lunak; ia adalah sistem fisik yang mengubah listrik menjadi representasi pengetahuan.
Untuk memahami kebutuhan energi LLM, penting membedakan dua fase yang sering disatukan dalam diskursus publik: training dan inference. Training adalah fase pembelajaran model, ketika miliaran parameter disesuaikan melalui optimasi berulang. Ini adalah fase paling intensif energi—berlangsung berminggu-minggu hingga berbulan-bulan pada klaster GPU skala besar, dengan konsumsi daya yang dapat mencapai puluhan megawatt. Jika dihitung sebagai energi total, satu siklus pelatihan dapat menembus puluhan gigawatt-jam. Angka ini setara dengan konsumsi listrik tahunan komunitas kecil.
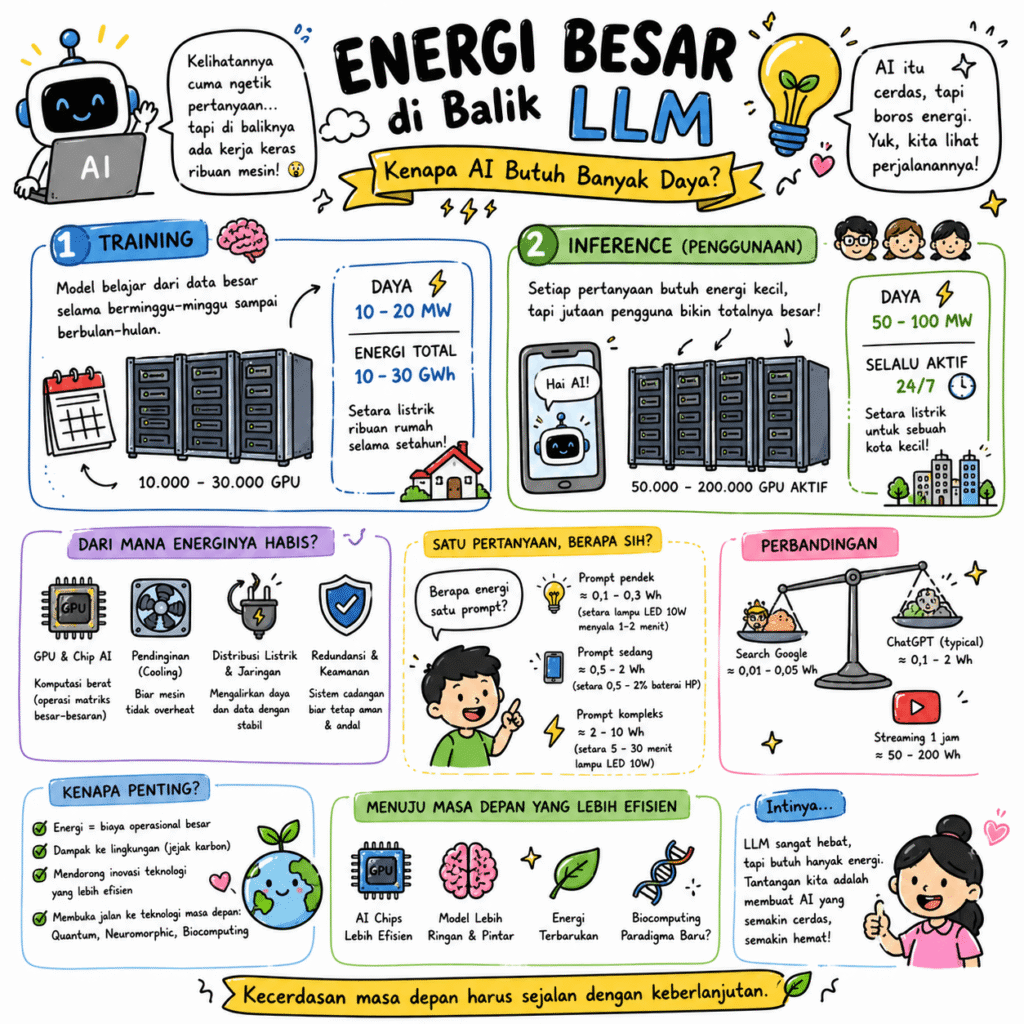
Sebaliknya, inference—fase ketika model digunakan oleh pengguna—terlihat lebih “ringan” pada tingkat transaksi. Satu permintaan biasanya hanya membutuhkan pecahan watt-hour. Namun, sifat LLM yang always-on dan melayani jutaan pengguna secara simultan membuat akumulasi energinya signifikan. Di sinilah paradoks muncul: konsumsi per interaksi kecil, tetapi total sistem besar. Dengan kata lain, skala adalah pengganda utama.
Secara teknis, sumber kebutuhan energi tersebut dapat ditelusuri ke karakter komputasi LLM yang sangat bergantung pada operasi aljabar linear berdimensi tinggi—perkalian matriks masif yang dieksekusi paralel pada GPU. Setiap token yang dihasilkan melibatkan lintasan komputasi melalui banyak lapisan jaringan saraf, masing-masing mengonsumsi siklus komputasi dan, pada akhirnya, energi. Efisiensi memang terus meningkat—arsitektur model, kompresi, quantization, dan optimasi perangkat keras telah menurunkan biaya per token—namun tren umum tetap jelas: semakin canggih model, semakin besar kebutuhan komputasinya.
Aspek lain yang sering terlewat adalah overhead pusat data. Energi yang digunakan tidak hanya untuk komputasi, tetapi juga untuk menjaga sistem tetap stabil: pendinginan, distribusi daya, redundansi jaringan. Indikator seperti Power Usage Effectiveness (PUE) menunjukkan bahwa setiap satuan energi komputasi biasanya diikuti tambahan 20–50% untuk operasional pendukung. Dengan demikian, diskusi energi LLM tidak lengkap tanpa melihat keseluruhan ekosistemnya.
Menariknya, jika dibandingkan dengan sistem biologis, kontrasnya cukup tajam. Otak manusia, dengan kemampuan kognitif yang masih menjadi standar emas kecerdasan umum, beroperasi pada kisaran 20 watt. Ia tidak melakukan perkalian matriks dalam pengertian komputasi digital, melainkan memanfaatkan dinamika neuron dan sinapsis yang sangat efisien secara energi. Perbandingan ini bukan untuk meromantisasi biologi, tetapi untuk menyoroti bahwa efisiensi komputasi bukanlah batas tetap—ia bergantung pada paradigma yang digunakan.
Dari sini, muncul pertanyaan yang lebih strategis daripada sekadar “berapa besar energi yang dibutuhkan?” yaitu: bagaimana arah evolusi komputasi jika energi menjadi kendala utama? Dalam beberapa tahun terakhir, kita melihat respons berlapis: pengembangan chip khusus AI yang lebih efisien, teknik pelatihan yang mengurangi kebutuhan iterasi, hingga pendekatan model distillation untuk menurunkan kompleksitas saat inference. Namun, di luar optimasi inkremental, mulai terlihat ketertarikan pada paradigma alternatif—neuromorphic computing, quantum computing, dan biocomputing—yang mencoba mendefinisikan ulang hubungan antara komputasi dan energi.
Dalam konteks ini, pembahasan LLM tidak lagi berhenti pada performa atau akurasi, tetapi melebar ke ekonomi energi. Setiap peningkatan kemampuan model memiliki konsekuensi biaya energi, dan pada skala global, ini berimplikasi pada infrastruktur listrik, keberlanjutan, hingga geopolitik teknologi. LLM menjadi contoh konkret bagaimana kecerdasan buatan, yang sering dipandang sebagai entitas abstrak, pada dasarnya adalah fenomena fisik yang terikat pada hukum energi.
Tulisan ini tidak bermaksud memberikan penilaian normatif, melainkan menawarkan kerangka baca: bahwa kemajuan AI selalu berjalan beriringan dengan konsumsi sumber daya. Jika dekade sebelumnya ditandai oleh pertumbuhan kapasitas komputasi, maka dekade berikutnya kemungkinan akan ditentukan oleh kemampuan kita mengelola—atau meredefinisi—biaya energi dari kecerdasan itu sendiri. Di titik ini, diskusi tentang efisiensi bukan lagi isu teknis semata, tetapi menjadi bagian dari arah masa depan teknologi.